Mutual Information Score — Feature Selection
using entropy from information theory

Hi everyone, how’s life? another day in paradise? Great.
Today we will look into a unique way of feature selection using mutual information.
Generally, there are two ways we look into a feature selection technique for numerical input data and a numerical target variable.
They are:
- Correlation Statistics
#Multi colineartiy — — — — — — — — — — — — — —
corr_matrix = X.corr().abs()
#select the upper triangle
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape),k=1).astype(np.bool))
#find features with correlation greater than 0.95
to_drop = [column for column in upper.columns if any(upper[column]>0.95)]
#drop the features
X.to_drop(to_drop,axis=1,inplace=True) - Mutual Information Statistics
- Others: Model Centric using Random Forest, Decision Trees etc. , but there is a catch, We need to train the model before we get to know the feature importance Thus it becomes computationally expensive at a production level.. Remember that! its a Data Science Architect Question.
- I have few of my own :) I named it as Auto Evaluate Feature Selection using Bregman divergence, Article Link: https://medium.com/@bobrupakroy/auto-evaluate-feature-selection-a1f74cbd119a
- Wrapper Functions: there are various wrapper functions like SelectKBest available with more flexibility to suit certain scenarios
- Under Development: TVS a method to discover feature importance using unsupervised learning.
The focus of this article will be the Mutual Information Feature Selection.
Mutual Information Feature Selection
Mutual information from the field of information theory is the application of information gain (typically used in the construction of decision trees) to feature selection.
Mutual information is calculated between two variables and measures the reduction in uncertainty for one variable given a known value of the other variable.
Mutual information is straightforward when considering the distribution of two discrete (categorical or ordinal) variables, such as categorical input and categorical output data. Nevertheless, it can be adapted for use with numerical input and output data. Mutual Information measures the entropy drops under the condition of the target value.
Simple explanation to this concept is this formula:
MI(feature;target) = Entropy(feature) — Entropy(feature|target)
The MI score will fall in the range from 0 to ∞.
The high value of Mi means a closer connection between the feature and the target indicating feature importance for training the model. However, the lower the MI score like 0 indicates a weak connection between the feature and the target.
Mutual Information Feature Selection for Regressor
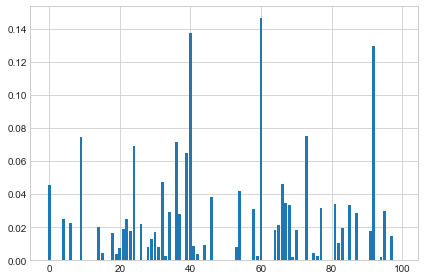
Modeling with all Features
#model using all input features
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error# load the dataset
X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1)# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)# fit the model
model = LinearRegression()
model.fit(X_train, y_train)# evaluate the model
yhat = model.predict(X_test)# evaluate predictions
mae = mean_absolute_error(y_test, yhat)
print('MAE: %.3f' % mae)
#0.08569191074140582
Modeling with correlated features with K = 88, here we will be using a wrapper function SelectKBest with score_func = f_regression similar to applying the regression model and then getting back the feature importance.
#model using 88 features chosen with correlation
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
# feature selection
def select_features(X_train, y_train, X_test):
# configure to select a subset of features
fs = SelectKBest(score_func=f_regression, k=88)
# learn relationship from training data
fs.fit(X_train, y_train)
# transform train input data
X_train_fs = fs.transform(X_train)
# transform test input data
X_test_fs = fs.transform(X_test)
return X_train_fs, X_test_fs, fs
# load the dataset
X, y = make_regression(n_samples=1000, n_features=100, n_informative=10, noise=0.1, random_state=1)# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)# feature selection
X_train_fs, X_test_fs, fs = select_features(X_train, y_train, X_test)# fit the model
model = LinearRegression()
model.fit(X_train_fs, y_train)# evaluate the model
yhat = model.predict(X_test_fs)# evaluate predictions
mae = mean_absolute_error(y_test, yhat)
#0.08569191074140582
Modeling with Mutual Information Features K=88,
here we also used the same SelectKBest wrapper function to get back the important features but this time we are using score_func = mutual_info_regression
Now let's apply the same in simple words with a dataset.
We will use the ames.csv dataset available at
https://github.com/rupak-roy/Mutual-Information-Feature-Selection
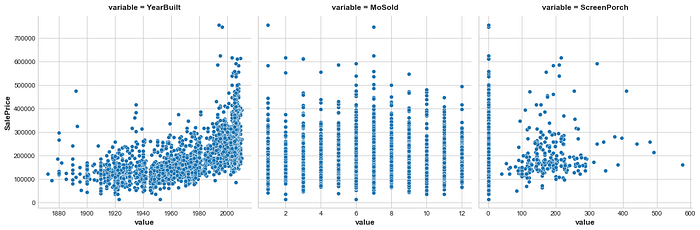
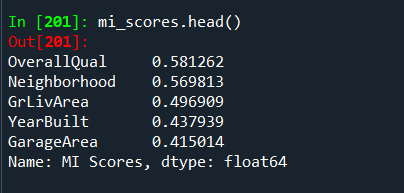
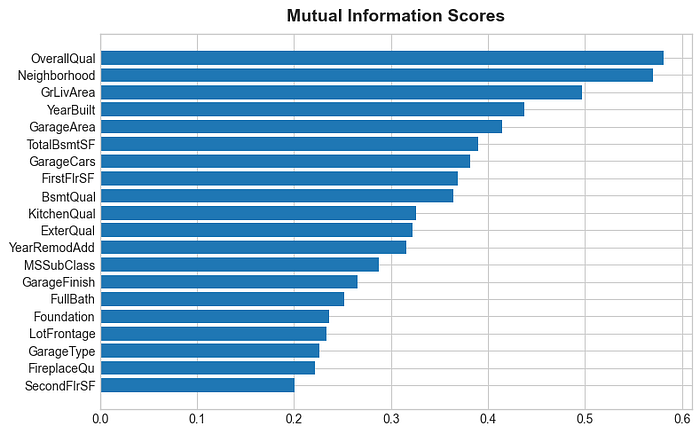
Next we will quickly go over a Mutual Information Classification Example.
Score_1: 0.9370629370629371
Score_2: 0.916083916083916
Score_3: 0.8391608391608392
Score_4: 0.916083916083916
Done. Thats it…………..
i hope you enjoyed likewise, i will try to bring as much as possible new contents across the data science realm and i hope the package will be useful at some point in your work. Because I believe machine learning is not replacing us, it’s about replacing the same iterative work that consumes time and much effort. So people should come to work to create innovations rather than be occupied in the same repetitive boring tasks.
Thanks again, for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.
Kaggle Implementation: https://www.kaggle.com/rupakroy/mutual-information-feature-selection-regression

