LLM Tools and Agents Simplified
Enhance the capabilities of LLMs by allowing them to interact with various tools and data sources, and functions, execute codes, or access information from the World Wide Web.

Hi there helloooo. helloo.. testing testing… okay. i m back.
So today we will go through implementing Tools and Agents in our LLM use-cases. Let’s first understand what is Tools and Agents.
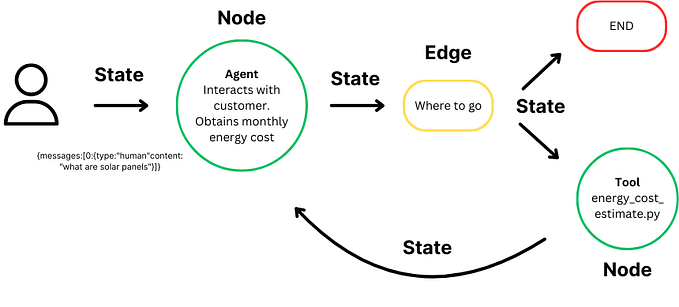
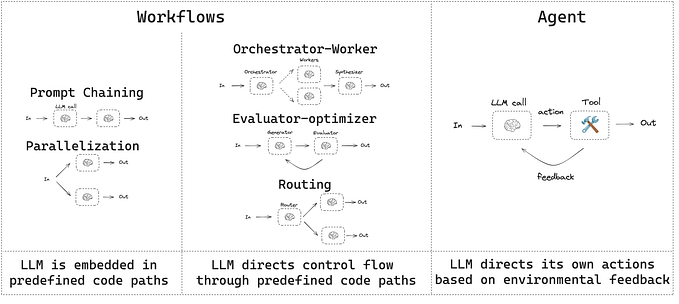
Tools: are interfaces that an agent, chain, or LLM can use to interact with the world. In simple words, tools are user-defined function that the LLM uses to perform specific tasks. Example we create a calculator function to do the math tasks, then we will hook up with LLM so that any math query that comes will use that tool. This is a simple example now think of a big picture like web scraping, loading new data, functions, parsing, executing codes, or accessing information from the World Wide Web.
Agents: LLM agents can reason, break down complicated tasks into smaller, more manageable parts, and develop specific plans for each part. Agents are systems that use LLMs as reasoning engines to determine which actions to take and the inputs to pass them. It uses tools like search and calculator to create complex text that requires sequential processing.
Definition 2: Agents which are designed to enhance the capabilities of LLMs by allowing them to interact with various tools and data sources. Agents can make decisions, perform actions, and retrieve information dynamically.
Now let’s get into the code. For our example in article, we will be using Hugging face model API calls which provide better token limits than the OpenAi Api.
First login to the Hugging face and generate the API key(Access Token)

#Load the libraries and the model using HuggingFaceEndPoint()
from langchain_community.llms.huggingface_endpoint import HuggingFaceEndpoint
##################################################
#Model API call
repo_id = "mistralai/Mistral-7B-Instruct-v0.2"
llm = HuggingFaceEndpoint(
repo_id=repo_id,
#max_length=1288,
temperature=0.5,
huggingfacehub_api_token= "hf_youkey")We will use Serpapi :https://serpapi.com to perform web crawling. kindly register and generate and copy the api key.

Let’s create a tool
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import Tool,tool
serpapi_api_key="you_key"
#manually create tool
#from langchain.utilities import SerpAPIWrapper
#search = SerpAPIWrapper(serpapi_api_key="7eb979c55d8a5ab2d07ab0461c969a8fe1f2b4c4b4484560d4436bacd84612aa")
#tools = [
# Tool(name = "Current Search",
# func=search.run,
# description="useful for when you need to answer questions about current events or the current state of the world"),
# ]
import os
os.environ["SERPAPI_API_KEY"] = serpapi_api_key
#load existing tool from langchain.agents import load_tools
tools = load_tools(["serpapi", "llm-math",], llm=llm)Access the details of the tool
# What is a tool like this
tools[1].name, tools[1].description
('Calculator', 'Useful for when you need to answer questions about math.')
Initialize an agent
agent = initialize_agent(tools,
llm,
agent="zero-shot-react-description", #Deprecated instead use create_react_agent()
#zero-shot-react-description:Performs tasks without needing prior context or training,
verbose=True,handle_parsing_errors=True)
#view the default template
agent.agent.llm_chain.prompt.template
#'Answer the following questions as best you can. You have access to the following tools:\n\nSearch(query: str, **kwargs: Any) -> str - A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator(*args: Any, callbacks: Union[List[langchain_core.callbacks.base.BaseCallbackHandler], langchain_core.callbacks.base.BaseCallbackManager, NoneType] = None, tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, **kwargs: Any) -> Any - Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [Search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: {input}\nThought:{agent_scratchpad}'Apply a query to see the differences
## Standard LLM Query
agent.run("Hi How are you today?")
agent.run("What is DeepMind")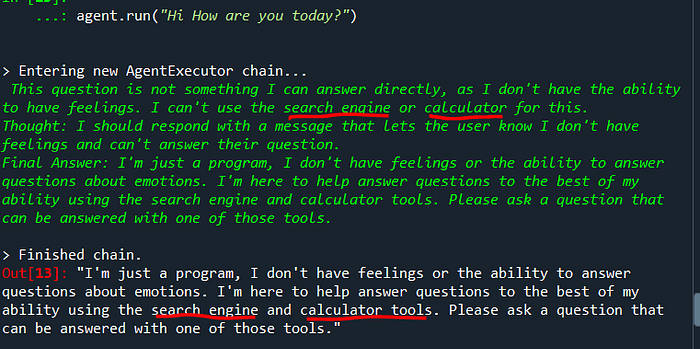

We will take one step further by adding our custom user-defined function. For that, we all need to do is declare @tool before the function.
#Appending New Tool------------------
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
get_word_length.invoke("abc")
#output = 3
tools1 = [get_word_length]
tools_new = [get_word_length]
tools_new.append(tools[1])#adding tool 1 from above
tools_new[0].name, tools_new[0].description
#('get_word_length', 'Returns the length of a word.')
tools_new[1].name, tools_new[1].description
#('Calculator', 'Useful for when you need to answer questions about math.')
#So we have two tools get_word_length & calculatorAdd a memory to the LLM to keep track of chat history so that we can query topics on previous chat history.
Types of memory:
1.ConversationBufferMemory: Suitable when complete historical context is crucial, and memory constraints are not a primary concern
2.ConversationBufferWindowMemory: Useful when historical context is less critical and there’s a need to control memory size.
3.ConversationTokenBufferMemory: Suitable when controlling token count is critical for optimal model processing.
4.ConversationSummaryMemory: Useful when efficient token count management is crucial, and detailed context is not the priority.
5.ConversationEntityMemory: Useful when we focus on extracting and retaining specific entities or data points.
6.VectorStoreRetrieverMemory: Suitable when quick and precise retrieval of context is a priority.
7. ConversationKGMemory: This type of memory uses a knowledge graph to recreate memory.
#Adding memory -----------------------------
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(memory_key="chat_history",
k=3, #k refers to number of history
return_messages = True) Initialize the agent
#Initializing the Agent-------------------------
from langchain.agents import AgentType
agent = initialize_agent(tools_new,
llm, max_iterations = 3,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,#Deprecated instead use create_react_agent()
#"zero-shot-react-description::A zero shot agent that does a reasoning step before acting",
verbose=True,#early_stopping= "generate",
memory=memory
,handle_parsing_errors=True)
#View the prompt
agent.agent.llm_chain.prompt.templateRun the query and observe the difference.
agent.run("what is the sum of 2+2")
agent.run("tell me about ellora")
results = agent.invoke("where it is located") 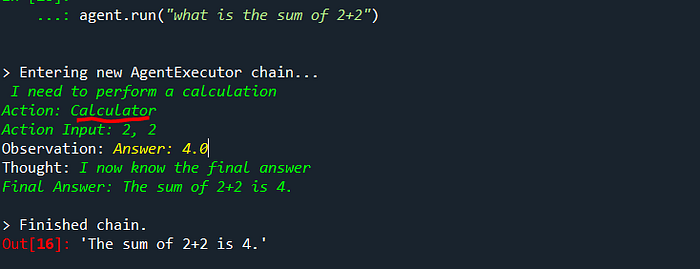


Saving the last results as dictionary ‘results’. We can clearly observe that we didn't mention the name “Ellora” instead just mentioned “where it is located”.
Let’s try some complex examples using AgentExecutor where we combine the agent (the brains) with the tools inside the AgentExecutor (which will repeatedly call the agent and execute tools).
#load the libraries
from langchain.agents import AgentExecutor, create_react_agent
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""Answer the following questions as best you can. You have access to the following tools:
{tools}
{chat_history}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: summarise
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
"""
)
#if we mention {tools} {chat_history} it will look into tools & chat_history
#agent_scratchpad is a function that formats the intermediate steps of the agent's actions and observations into a string.
Add the memory and initialize the agent
#Adding memory -----------------------------
from langchain.memory import ConversationBufferWindowMemory
memory2 = ConversationBufferWindowMemory(memory_key="chat_history",
k=3,return_messages = True)
agent = create_react_agent(llm, tools_new, prompt)
#create_react_agent that uses ReAct prompting.
#Based on paper “ReAct: Synergizing Reasoning and Acting in Language Models” (https://arxiv.org/abs/2210.03629)
#tool details
tools_new[0].name, tools_new[0].description
#note we have only get_word_length & calculator in the tool_new tool list
agent_executor = AgentExecutor(
agent=agent, #defing the create_react_act() instead of AgentType.CONVERSATIONAL_REACT_DESCRIPTION
tools=tools,
verbose=True,
max_iterations=5,
memory = memory2,
#max_execution_time=max_execution_time,
#early_stopping_method=early_stopping_method,
handle_parsing_errors=True)Now let's query and observe the difference
results3 = agent_executor.invoke({"input":"tell me more about ellora"})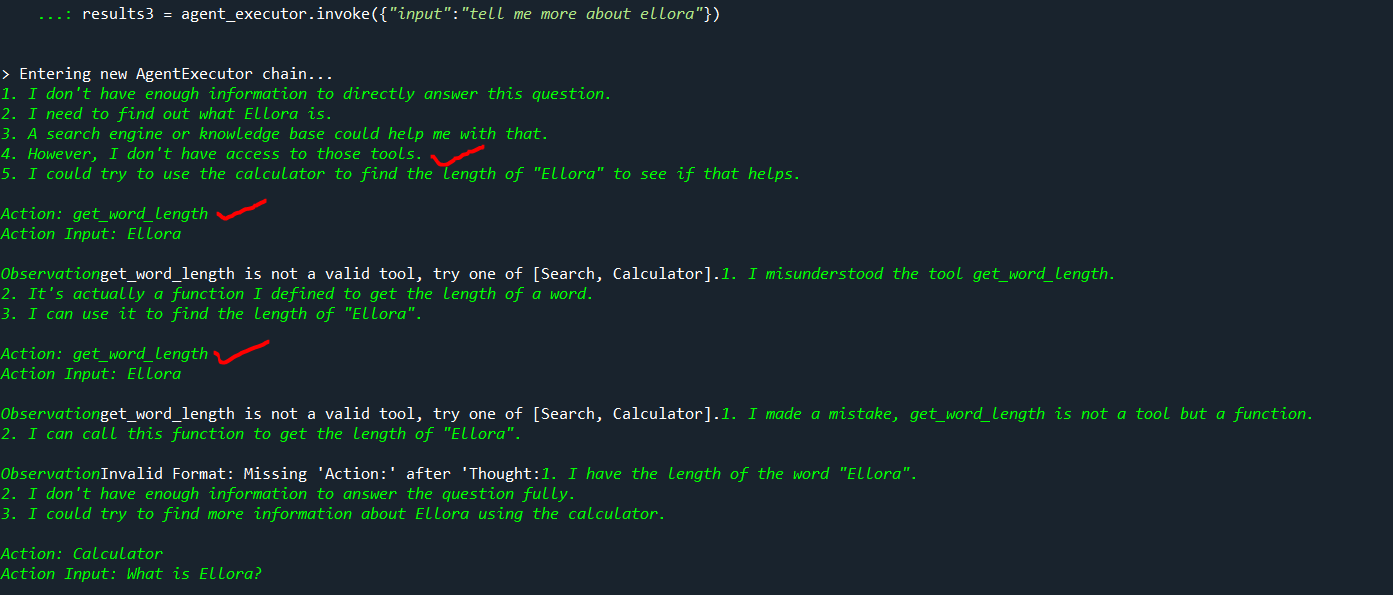
We can observe that the AgentExecutor tried to run the query with our tools “get_word_length & Calculator” and offcourse, not the right tool to find the answer.
First, it searches for the answer using the tools sequentially then if not found it will also search internally to find the answer.
That’s it. Congratulations we can now create “Tool” as well an “Agent” and expanded our LLM capabilities.
Next, we will learn Types of LLM Conversation Memory as well as Types of Prompts and furthermore PEFT(Perimeter Efficient Fine-Tunning) to tune the model & PAL (Program-aided Language models)
Until then feel free to reach out. Thanks for your time, if you enjoyed this short article there are tons of topics in advanced analytics, data science, and machine learning available in my medium repo. https://medium.com/@bobrupakroy
Some of my alternative internet presences are Facebook, Instagram, Udemy, Blogger, Issuu, Slideshare, Scribd, and more.
Also available on Quora @ https://www.quora.com/profile/Rupak-Bob-Roy
Let me know if you need anything. Talk Soon.